概述
rpc和http都是属于应用层、 HTTP/1.1协议的内容非常的冗余,显得非常啰嗦。因为为了适用于多个平台。
而rpc定制化程度更高,可以使用体积更小的序列化协议去保存这些数据结构。同时不需要考虑各种浏览器的行为,比如重定向跳转之类的,因此性能会更好一点。
rpc的通信流程
在实现一个rpc之前我们有必要了解一下它的大概工作流程
rpc能实现调用远程方法就跟调用本地(同一个项目中的方法)一样,发起调用请求的那一方叫做调用方,被调用 的一方叫做服务提供方。 发起远程调用的核心是网络通信,整个调用过程中的一些流程和细节:
- 传输协议:既然 rpc 存在的核心目的是为了实现远程调用,既然是远程调用那肯定就需要通过网络来传输数 据,并且 rpc 常用于业务系统之间的数据交互,需要保证其可靠性,所以 rpc 一般默认采用 TCP 来传输。事实 上。我们常用的 HTTP 协议也是建立在 TCP 之上的。选择tcp的核心原因还是因为他的效率要比很多应用层协议高 很多。
- 封装一个可用的协议:选择了合适的传输层协议之后,我们需要基于此建立一个我们自己的通用协议,和http 一样需要封装自己的应用层协议。
- 序列化:网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象。对象是肯定没法直接在网络 中传输的,需要提前把它转成可传输的二进制,并且要求转换算法是可逆的,这个过程我们一般叫做“序列化”。
- 压缩:如果我们觉得序列化后的字节数组体积比较大,我们还可以对他进行压缩,压缩后的字节数组体积更 小,能在传输的过程中更加节省带宽和内存。
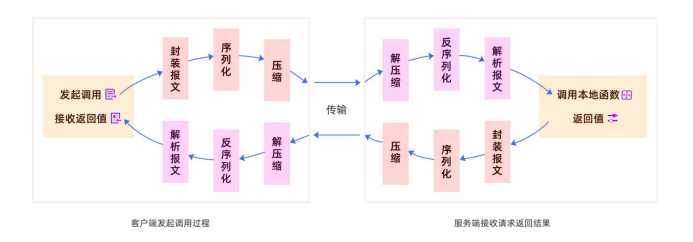
协议定制
既然通过网络进行传输,而我们并不打算使用http,那么我们有必要定制一个属于我们的协议
head
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public class RpcRequest {
//请求id
private long requestId;
//请求类型
private byte requestType;
//压缩类型
private byte compressType;
//序列化方式
private byte serializeType;
//消息体
private RequestPayload requestPayload;
//时间戳
private long timeStrap;
}
|
body
1
2
3
4
5
6
7
8
9
10
11
12
| public class RequestPayload implements Serializable {
//接口名字
private String interfaceName;
//方法的名字
private String methodName;
//参数类型
private Class<?>[] paramType;
//参数值
private Object[] paramValue;
//返回值
private Class<?> returnType;
}
|
序列化
由于在网络传输中,传输的是二进制,而我们的java程序识别的是class类,所以我们有必要将二进制反序列化为对象,或者将对象序列化为二进制
网络传输中,我们不能直接将堆内存的对象实例直接进行传输,而是需要将其序列化成一组二进制数据,这样的二 进制数据可以是字符序列,最简单的莫过于我们熟悉的json字符序列,当然,事实上只要是一组可逆的转换过程都 可以,如:
- jdk的ObjectInputStream
- Hession
- json
- protobuf等
事实上我们会发现一个问题,不同的序列化方式,在序列化后的信息密度是不一样的,像json这样,我们可以轻易 读懂,也就意味着他的信息密度是最小的,也就是序列化后的体积是最大的,传输传输过程中需要的带宽也是最大 的,选用什么样的序列化方式,也要和我们的系统的特性相结合。当然为了让我们的框架更加的灵活和具备可扩展 性,我们可以灵活配置序列化方式。
压缩
一个消息的body一般是我们要传输的数据,是消息协议当中最大的一个部分,为了加快消息的传递速度,我们需要对消息进行压缩
如果我们觉得序列化后的二进制内容体积任然比较大,任然不能支持当前的业务容量,我们可以选择对序列化的结 果进行压缩,但是开启压缩一定要注意,这个操作本是就是一个cpu资源换取存储和带宽资源的操作,要判断当前 的业务是更需要cpu资源还是内存资源。 通常我们使用gzip的方式进行压缩:
服务注册发现
内容包括:
- 服务提供方将服务注册到注册中心中
- 消费端拉取服务列表
注册中心统一接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public interface Registry {
/**
* 服务注册
* @param serviceConfig 服务配置内容
*/
void registry(ServiceConfig<?> serviceConfig);
/**
* 查询到一个可用的服务
*
* @param serviceName 服务名称
* @return ip和端口
*/
List<InetSocketAddress> lookUp(String serviceName,String group);
}
|
不同的注册中心的实现方式都继承此接口,规范其行为,后期通过配置,即可获得不同的注册中心实现
Netty(立消费端和服务提供 方的之间的长连接)
netty主要用于消息协议的传输,以消费者为例:
- 消费者先封装一个协议包,里面有自己想调用的接口和对应服务提供者的地址,然后对协议包中的body进行编码压缩,接下来将协议包发送出去
- 服务提供者接收到消费者发送过来的协议包,对消息进行解码
- 协议包解码后获得了相关参数,接下来在服务端调用相关方法,返回方法调用后的结果
- 消息在发送出去之前先编码压缩,便于更快的到达消费者
- 消费者接收到协议包前先解码
- 消费者处理结果
此处不给出实现代码,只给出流程代码
消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| /**
* 消费者通道初始化器类,用于在Netty的TCP客户端通道建立时配置其处理链。
* 继承自ChannelInitializer,重写initChannel方法以初始化SocketChannel的处理链。
*/
public class ConsumerChannelInitializer extends ChannelInitializer<SocketChannel> {
/**
* 当通道被初始化时,此方法被调用。它负责添加一系列处理器到通道的处理链中。
*
* @param socketChannel 需要被初始化的SocketChannel对象。
* @throws Exception 如果初始化过程中发生错误。
*/
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
// 初始化通道的处理链
socketChannel.pipeline()
// 添加日志处理器,用于记录通道活动的日志,级别为DEBUG
// netty自带的日志输出处理器
.addLast(new LoggingHandler(LogLevel.DEBUG))
// 添加请求编码器,用于将客户端的RPC请求编码为适合网络传输的格式
// 出站编码器
.addLast(new RpcRequestEncoder())
// 添加响应解码器,用于将服务端返回的RPC响应解码为客户端可处理的格式
// 入站解码器
.addLast(new RpcResponseDecoder())
// 添加业务逻辑处理器,用于处理客户端接收到的RPC响应
// 结果处理
.addLast(new ConsumerChannelInboundHandler());
}
}
|
服务提供者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public class ProviderChannelInitializer extends ChannelInitializer<SocketChannel> {
/**
* 当一个新的SocketChannel被创建时,该方法会被调用以初始化其pipeline。
* 这里,我们添加了几个处理程序来处理进来的RPC请求并发送响应。
*
* @param socketChannel 新创建的SocketChannel实例
* @throws Exception 如果初始化过程中发生任何异常
*/
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
// 初始化SocketChannel的处理链
socketChannel.pipeline()
// 添加日志记录处理程序,用于记录网络通信的详细信息
.addLast(new LoggingHandler(LogLevel.DEBUG))
// 添加RPC请求解码器,用于将进来的字节流解码为可处理的RPC请求对象
.addLast(new RpcRequestDecoder())
// 添加方法调用处理程序,实际处理RPC请求并调用相应的服务方法
.addLast(new MethodCallHandler())
// 添加RPC响应编码器,用于将处理结果编码为字节流准备发送
.addLast(new RpcResponseEncoder());
}
}
|
代理模式
消费者在进行方法调用时,只是调用而已,并不关心和netty建立连接等,这些操作由代理替我们完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
log.debug("method:" + method.getName());
log.debug("args:" + Arrays.toString(args));
// 最大重试次数
int tryTimes = 3;
// 重试间隔时间
int intervalTime = 2000;
while (true) {
// 封装请求Payload
RequestPayload requestPayload = RequestPayload.builder()
.interfaceName(interfaceRef.getName())
.methodName(method.getName())
.paramType(method.getParameterTypes())
.paramValue(args)
.returnType(method.getReturnType())
.build();
// 创建MRPC请求对象
MrpcRequest mrpcRequest = MrpcRequest.builder()
.requestId(MrpcBootStrap.getInstance().getConfiguration().getIdGenerator().getId())
.requestType(RequestType.REQUEST.getI())
.compressType(CompressorFactory
.getCompressorWrapper(MrpcBootStrap.getInstance().getConfiguration().getCompressType())
.getCode())
.serializeType(SerializeFactory
.getSerialize(MrpcBootStrap.getInstance().getConfiguration().getSerializeType())
.getCode())
.requestPayload(requestPayload)
.build();
MrpcBootStrap.THREAD_LOCAL_CACHE.set(mrpcRequest);
// 从注册中心获取服务地址
InetSocketAddress address =
MrpcBootStrap.getInstance()
.getConfiguration().getBalancer()
.selectServiceAddress(interfaceRef.getName(),group);
log.debug("拿到了可用服务【{}】",address);
// 获取或创建对应服务地址的熔断器
Map<SocketAddress, CircuitBreaker> everyIpCircuitBreaker = MrpcBootStrap.getInstance()
.getConfiguration().getEveryIpCircuitBreaker();
CircuitBreaker circuitBreaker = everyIpCircuitBreaker.get(address);
if (circuitBreaker == null) {
circuitBreaker = new CircuitBreaker(1,0.5F);
everyIpCircuitBreaker.put(address,circuitBreaker);
}
try {
// 获取通道并发送请求
Channel channel = getChannel(address);
log.debug("与【{}】建立了可用的通道",address);
CompletableFuture<Object> completableFuture = new CompletableFuture<>();
MrpcBootStrap.PENDING_FUTURE.put(mrpcRequest.getRequestId(), completableFuture);
channel.writeAndFlush(mrpcRequest).addListener((ChannelFutureListener) promise ->{
if (!promise.isSuccess()){
completableFuture.completeExceptionally(promise.cause());
}
});
// 等待响应并返回结果
Object result = completableFuture.get(10, TimeUnit.SECONDS);
circuitBreaker.recordRequest();
return result;
} catch (RuntimeException | InterruptedException | ExecutionException | TimeoutException e) {
// 处理重试逻辑
// 次数减一,并且等待固定时间
tryTimes--;
circuitBreaker.recordErrorRequest();
try {
Thread.sleep(intervalTime);
} catch (InterruptedException ex) {
log.error("在进行重试时发生异常.", ex);
}
// 如果重试次数用尽,抛出异常
if (tryTimes < 0) {
log.error("对方法【{}】进行远程调用时,重试{}次,依然不可调用",
method.getName(), tryTimes, e);
break;
}
log.error("在进行第{}次重试时发生异常.", 3 - tryTimes, e);
}
}
throw new RuntimeException("执行远程方法" + method.getName() + "调用失败。");
}
|
负载均衡
基于一致性哈希算法的负载均衡器
哈希算法
Hash函数最大的作用是散列,或者说是将一系列在形式上具有相似性质的数据,打散成随机的、均匀分布的数据。
举例:
如果我们给每个请求生成一个Key,只要使用一个非常简单的Hash算法Group = Key % N来实现请求的负载均衡
哈希算法的缺点
当我们增加或者移除服务器时,之前计算过的哈希值全部不生效,为了解决此问题,引入一致性哈希
一致性哈希
我们想象出一个环,每个服务器我们放在这个环上面
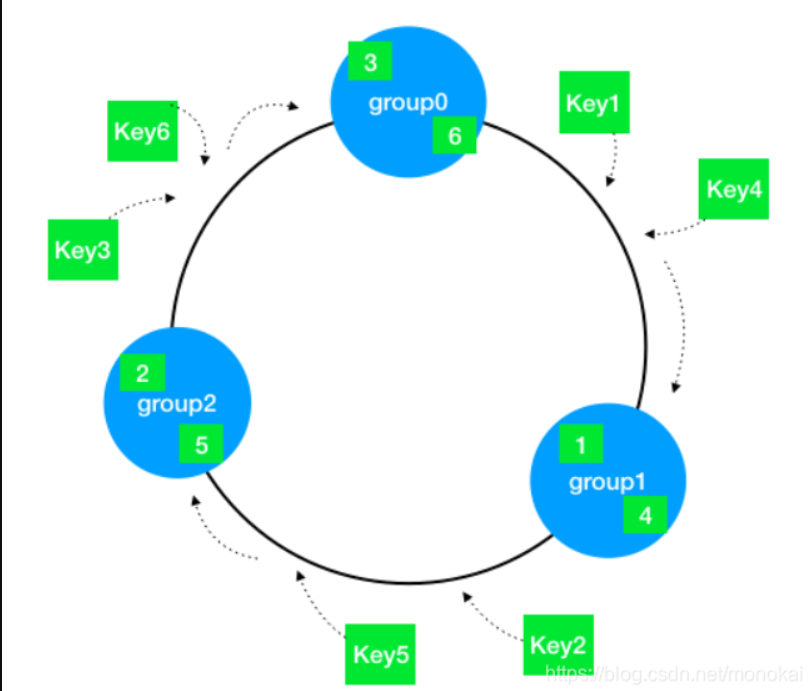
整个Hash空间被构建成一个首尾相接的环,使用一致性Hash时需要进行两次映射。
第一次,给每个节点(集群)计算Hash,然后记录它们的Hash值,这就是它们在环上的位置。
第二次,给每个Key计算Hash,然后沿着顺时针的方向找到环上的第一个节点,就是该Key储存对应的集群。
可以想象,当节点被删除时,其余节点在环上的映射不会发生改变,只是原来打在对应节点上的Key现在会转移到顺时针方向的下一个节点上去。增加一个节点也是同样的,最终都只有少部分的Key发生了失效。不过发生节点变动后,整体系统的压力已经不是均衡的了。
问题与优化
最基本的一致性Hash算法直接应用于负载均衡系统,效果仍然是不理想的,存在诸多问题,下面就对这些问题进行逐个分析并寻求更好的解决方案。
数据倾斜
如果节点的数量很少,而hash环空间很大(一般是 0 ~ 2^32),直接进行一致性hash上去,大部分情况下节点在环上的位置会很不均匀,挤在某个很小的区域。最终对分布式缓存造成的影响就是,集群的每个实例上储存的缓存数据量不一致,会发生严重的数据倾斜。
缓存雪崩
如果每个节点在环上只有一个节点,那么可以想象,当某一集群从环中消失时,它原本所负责的任务将全部交由顺时针方向的下一个集群处理。例如,当group0退出时,它原本所负责的缓存将全部交给group1处理。这就意味着group1的访问压力会瞬间增大。设想一下,如果group1因为压力过大而崩溃,那么更大的压力又会向group2压过去,最终服务压力就像滚雪球一样越滚越大,最终导致雪崩。
引入虚拟节点
解决上述两个问题最好的办法就是扩展整个环上的节点数量,因此我们引入了虚拟节点的概念。一个实际节点将会映射多个虚拟节点,这样Hash环上的空间分割就会变得均匀。
同时,引入虚拟节点还会使得节点在Hash环上的顺序随机化,这意味着当一个真实节点失效退出后,它原来所承载的压力将会均匀地分散到其他节点上去。
优雅缩扩容
当我们增加/移除了新的服务器节点后,还是有一小部分key是无法使用的,我们需要进行数据迁移,这个过程还是有点耗时的。数据迁移的过程中无法访问到这些数据如何解决?
1.高频Key预热
负载均衡器作为路由层,是可以收集并统计每个缓存Key的访问频率的,如果能够维护一份高频访问Key的列表,新的集群在启动时根据这个列表提前拉取对应Key的缓存值进行预热,便可以大大减少因为新增集群而导致的Key失效。
2.历史Hash环保留
回顾一致性Hash的扩容,不难发现新增节点后,它所对应的Key在原来的节点还会保留一段时间。因此在扩容的延迟时间段,如果对应的Key缓存在新节点上还没有被加载,可以去原有的节点上尝试读取。
举例,假设我们原有3个集群,现在要扩展到6个集群,这就意味着原有50%的Key都会失效(被转移到新节点上),如果我们维护扩容前和扩容后的两个Hash环,在扩容后的Hash环上找不到Key的储存时,先转向扩容前的Hash环寻找一波,如果能够找到就返回对应的值并将该缓存写入新的节点上,找不到时再透过缓存
对比:HashSlot
了解了一致性Hash算法的特点后,我们也不难发现一些不尽人意的地方:
整个分布式缓存需要一个路由服务来做负载均衡,存在单点问题(如果路由服务挂了,整个缓存也就凉了)
Hash环上的节点非常多或者更新频繁时,查找性能会比较低下
针对这些问题,Redis在实现自己的分布式集群方案时,设计了全新的思路:基于P2P结构的
HashSlot
类似于Hash环,Redis Cluster采用HashSlot来实现Key值的均匀分布和实例的增删管理。
首先默认分配了16384个Slot(这个大小正好可以使用2kb的空间保存),每个Slot相当于一致性Hash环上的一个节点。接入集群的所有实例将均匀地占有这些Slot,而最终当我们Set一个Key时,使用CRC16(Key) % 16384来计算出这个Key属于哪个Slot,并最终映射到对应的实例上去。
那么当增删实例时,Slot和实例间的对应要如何进行对应的改动呢?
举个例子,原本有3个节点A,B,C,那么一开始创建集群时Slot的覆盖情况是:
1
2
3
| 节点A 0-5460
节点B 5461-10922
节点C 10923-16383
|
现在假设要增加一个节点D,RedisCluster的做法是将之前每台机器上的一部分Slot移动到D上(注意这个过程也意味着要对节点D写入的KV储存),成功接入后Slot的覆盖情况将变为如下情况:
1
2
3
4
5
| 节点A 1365-5460
节点B 6827-10922
节点C 12288-16383
节点D 0-1364,5461-6826,10923-12287
|
同理删除一个节点,就是将其原来占有的Slot以及对应的KV储存均匀地归还给其他节点。
P2P节点寻找
现在我们考虑如何实现去中心化的访问,也就是说无论访问集群中的哪个节点,你都能够拿到想要的数据。其实这有点类似于路由器的路由表,具体说来就是:
每个节点都保存有完整的HashSlot - 节点映射表,也就是说,每个节点都知道自己拥有哪些Slot,以及某个确定的Slot究竟对应着哪个节点。
无论向哪个节点发出寻找Key的请求,该节点都会通过CRC(Key) % 16384计算该Key究竟存在于哪个Slot,并将请求转发至该Slot所在的节点。
总结一下就是两个要点:映射表和内部转发,这是通过著名的Gossip协议来实现的。
心跳
需要有一种机制来判断服务是否处于正常上线的状态
一个服务可能有多台实例,需要定期对这些实例发送心跳来判断这些实例是否可用
流程:
1、根据服务名获取所有的实例
2、连接每一个实例,保存chanel
3、定时任务遍历发送心跳包异步等待结果
4、若心跳超时进入重试操作
5、将不可用的心跳移除
熔断限流
熔断器
当服务不可用时应拒绝服务,等待可用时再开启服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class CircuitBreaker {
// 熔断器状态,true表示熔断器打开,阻止请求
//熔断器是否开启
private volatile boolean isOpen = false;
// 记录总请求次数
//请求数
private AtomicInteger requestCount = new AtomicInteger(0);
// 记录错误请求次数
//异常请求数
private AtomicInteger errorRequest = new AtomicInteger(0);
// 允许的最大错误请求次数
private int maxErrorRequest;
// 允许的最大错误率
private float maxErrorRate;
}
|
当有错误请求时执行errorRequest.incrementAndGet();
当错误请求达到设置的最大数量时拒绝服务
1
2
3
4
5
6
| // 检查当前错误请求数量是否超过预设的最大错误请求阈值。
// 触发的阈值
if (errorRequest.get() > maxErrorRequest){
isOpen = true;
return true;
}
|
当错误请求和请求总数达到阈值时拒绝请求
1
2
3
4
5
6
| // 如果错误请求数量大于0且请求总数大于0,并且错误率超过预设的最大错误率,则开启熔断器。
if (errorRequest.get() > 0 && requestCount.get() > 0
&& errorRequest.get() / (float)requestCount.get() > maxErrorRate){
isOpen = true;
return true;
}
|
令牌桶限流器
思想:
以恒定的速率去生成令牌,放入令牌桶中;
请求在获得令牌后才能执行;
请求获取不到令牌则阻塞;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class TokenBuketRateLimiter implements RateLimiter{
// 令牌桶中当前的令牌数量
//令牌数
private int tokens;
// 令牌桶的容量
//桶容量
private final int capacity;
// 每秒添加的令牌数量
//增加令牌的速率
private final int rate;
// 上一次添加令牌的时间戳
//上一次放令牌的时间
private long lastTokenTime;
}
|
核心代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| /**
* 判断是否允许进行请求。
* 该方法实现了令牌桶算法,用于限流。只有当桶中有令牌时,才允许请求通过。
* 如果桶中没有令牌,则请求被拒绝。每次请求都会尝试获取一个令牌。
*
* @return 如果允许请求,则返回true;否则返回false。
*/
public synchronized boolean allowRequest() {
// 获取当前时间,用于计算时间间隔。
// 获取当前时间
//判断是否需要添加令牌
long currentTime = System.currentTimeMillis();
// 计算自上一次添加令牌以来的时间间隔。
// 计算自上一次添加令牌以来的时间间隔
long timeInterval = currentTime - lastTokenTime;
// 如果时间间隔大于等于1秒,说明需要添加新的令牌。
// 如果时间间隔大于等于1秒,添加新的令牌
//如果时间大于等于速率就添加令牌
if (timeInterval >= 1000) {
// 计算应添加的令牌数量。
// 计算应添加的令牌数量
int addNewTokens = (int) (timeInterval / 1000 * rate);
// 确保令牌数量不超过桶的容量。
// 确保令牌数量不超过桶的容量
tokens = Math.min(capacity, tokens + addNewTokens);
// 更新上一次添加令牌的时间。
lastTokenTime = currentTime;
}
// 如果桶中有令牌,消耗一个令牌并允许请求通过。
// 如果令牌桶中有令牌,消耗一个令牌并允许请求通过
if (tokens > 0) {
tokens--;
return true;
}
// 桶中没有令牌,请求被拒绝。
// 令牌桶中没有令牌,请求被限流
return false;
}
|
代理调用方法
消费者调用服务接口不关心如何去调用,只需要关注调用的结果
如何去调用交由代理来实现
流程:
1、初始化重试机制:设置最大重试次数为3,重试间隔时间为2秒。
2、构建RPC请求:
封装请求Payload,包括接口名、方法名、参数类型、参数值和返回类型。
创建Request对象,设置请求ID、请求类型、压缩类型、序列化类型以及请求Payload。
3、获取服务地址:从注册中心选择服务地址。
4、处理熔断器:
获取或创建针对该服务地址的熔断器。
如果熔断器打开且请求非心跳包,则延迟一段时间后重置熔断器,并抛出异常。
建立通道并发送请求:
5、通过getChannel方法获取与服务端通信的Channel。
使用CompletableFuture异步处理响应。
6、将Request写入并刷新到Channel,监听写操作状态。
7、等待响应并处理结果:
等待最多10秒获取响应结果。
成功则返回结果,否则捕获异常。
8、重试逻辑:
捕获运行时异常、中断异常、执行异常或超时异常时,减少剩余重试次数。
记录错误请求至熔断器,等待指定间隔时间后重试。
若重试次数耗尽,记录日志并退出循环。
9、异常处理:如果所有尝试均失败,抛出运行时异常,指示远程方法调用失败。






